Retrieval Augmented Generation (RAG)
Supercharge your AI with context-aware, data-grounded intelligence
Retrieval Augmented Generation (RAG) is revolutionizing how organizations tap into their data for smarter, more reliable AI. By combining the retrieval power of search with the generative capabilities of advanced AI models, RAG bridges the gap between static language models and your ever-evolving proprietary knowledge.
At PG Services, we help you deploy RAG solutions using Elasticsearch, vector databases, NLP, and large language models (LLMs) to create next-gen customer and employee experiences. Whether enhancing internal knowledge tools or customer-facing chat, we ensure your AI is accurate, contextual, and grounded in your data.
What is Retrieval Augmented Generation (RAG)?
RAG is an approach that connects retrieval systems (like Elasticsearch) to generation models (like large language models) to produce richer, more relevant answers.
It works in two stages:
Retrieval: A search engine queries proprietary or external datasets to fetch the most relevant documents, passages, or data points related to the user’s input. This uses techniques such as semantic search and vector similarity search to understand meaning and context, not just keywords.
Generation: A large language model (LLM) — trained on vast text corpora — takes the retrieved content and uses it as context to generate clear, human-like responses.
Unlike traditional LLM-only approaches, RAG supplements the model’s static knowledge with real-time, domain-specific information. This means your AI isn’t limited by what it learned months or years ago — it continuously grounds answers in your current data.
How does RAG work with Elasticsearch?
Elastic’s Elasticsearch Relevance Engine™ (ESRE) and rich ecosystem of NLP and vector tools make it an ideal foundation for building RAG systems. Here’s how:
Data Storage & Retrieval
Store proprietary documents, knowledge bases, structured or unstructured data in Elasticsearch.
Semantic & Vector Search
Use vector encoders (like ELSER, BERT, or custom transformers) to create embeddings, enabling similarity-based, meaning-driven retrieval.
Context Injection
Pass retrieved context into an LLM like GPT or LLaMA to generate tailored, accurate responses.
Security-Aware & Compliant
Elasticsearch allows for document-level security, ensuring sensitive data is only retrieved and used where appropriate.
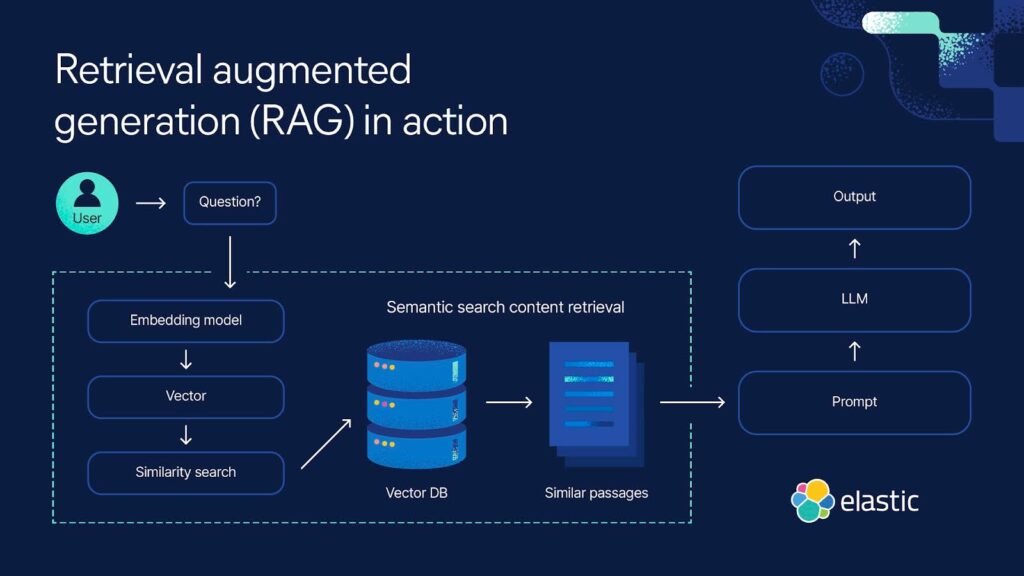
The result? A system that can cite sources, ground responses in your organization’s unique data, and reduce hallucinations or inaccuracies common to standalone LLMs.
Core Technologies in Your RAG Stack
Large Language Models (LLMs)
Deep-learning models (like GPT, BERT, PaLM, Claude) trained on enormous datasets that understand and generate text. They use transformer architectures with self-attention to capture context.
Natural Language Processing (NLP)
NLP enables understanding of language, sentiment, entities, and syntax. Elastic supports transformer-based NLP directly in Elasticsearch for tasks like classification, summarization, and question answering.
Semantic & Vector Search
Beyond keyword search — semantic search deciphers user intent and contextual meaning using embeddings and k-NN algorithms on vectors. This is foundational to RAG, ensuring retrieval isn’t literal but meaningful.
Generative AI
Generative AI models produce new text, code, images, or audio. In RAG, LLMs generate natural-sounding answers using context retrieved by Elasticsearch.
Retrieval-First Architecture
Unlike fine-tuning that bakes domain knowledge into the model weights (costly and static), RAG retrieves fresh, relevant information on the fly. This means:
- Reduced cost (less re-training)
- Up-to-date context (draws on latest documents)
- Source-backed outputs (can cite references)
Why RAG Matters for Your Business
More Accurate & Contextual
Your AI system uses both general world knowledge and your specific proprietary data to give tailored, fact-grounded responses.
Faster to Deploy & More Cost-Effective
Skip the heavy compute costs of re-training LLMs on every new dataset. Retrieval plugs in new data instantly.
Cites Sources for Trust
Because answers reference retrieved documents, users can trace back to original sources for validation.
Handles Complex Queries
For specialized industries (finance, healthcare, law), RAG helps LLMs navigate questions standard models would hallucinate.
Improves over Time
By updating your indexed data, your system continually improves its answers without re-training the underlying model.
Typical RAG Use Cases
Enterprise Knowledge Chatbots
Combine company manuals, support docs, and policies to generate precise answers.
Legal & Compliance
Navigate case files or regulations to deliver citations-backed responses.
Healthcare
Provide context-aware summaries or guidance using patient docs & clinical literature.
Technical Support
Troubleshoot using historical logs and knowledge base articles.
Retail & Commerce
Personalized shopping assistants that understand customer preferences and inventory details.
Why Partner with PG Services?
As specialists in Elastic Stack, machine learning, and AI integrations, we:
- Architect and deploy retrieval pipelines, from ingestion and vectorization to secure indexing.
- Integrate with your preferred LLMs (via APIs or private deployments).
- Build custom dashboards to monitor queries, usage, and ROI.
- Ensure security policies & compliance across sensitive datasets.
- Provide ongoing optimization so your RAG solutions stay ahead.

Ready to transform your data into intelligent, grounded answers?
Contact PG Services today to explore how RAG with Elasticsearch, NLP, and Generative AI can empower your team, delight your customers, and future-proof your operations.